
The Unstable Nature of Modern LLM Systems
In recent years, LLM-driven systems have rapidly transitioned from experimental prototypes to production-critical infrastructure. However, as LLM capabilities evolve, stability is no longer guaranteed. Models are continuously updated, refined, or deprecated, and therefore, systems built around a fixed LLM often become fragile over time.
Moreover, even without visible API changes, behavior can shift unexpectedly. Prompts that once performed reliably may begin to degrade, while outputs become inconsistent or harder to validate. As a result, teams building modern applications must reconsider how they integrate and manage LLM dependencies. Instead of treating an LLM as a static component, it should be viewed as a dynamic layer within a larger system. Consequently, designing for adaptability becomes essential to maintaining performance, reliability, and long-term scalability.
Why LLM Migration Is No Longer Optional
As LLM ecosystems continue to evolve, migration is no longer a periodic task but an ongoing necessity. Previously, teams could rely on stable versions for extended periods; however, modern LLM providers frequently introduce updates that alter behavior, cost structures, and performance. Therefore, staying on outdated models increasingly exposes systems to operational risks.
Moreover, LLM-powered applications, especially those embedded in scalable platforms like web applications, depend on consistent outputs to maintain user trust. When models change, even subtle differences can cascade into larger failures. Consequently, proactive LLM migration ensures systems remain reliable and adaptable. Instead of reacting to breakages, forward-looking teams continuously evaluate and update their LLM integrations to maintain stability and performance.
The Shift from Model Stability to Continuous Change
Earlier, LLM integrations were treated similarly to traditional APIs, where stability was assumed after deployment. However, this assumption no longer holds. Modern LLM systems evolve continuously, and therefore, their behavior can shift even without explicit version changes.
Additionally, providers frequently release improved models while retiring older ones. As a result, teams must adapt to a constantly moving baseline rather than a fixed reference point. This shift fundamentally changes how systems should be designed and maintained. Consequently, engineering teams must embrace continuous adaptation. Instead of optimizing once, they must regularly reassess prompts, outputs, and system behavior to ensure alignment with evolving LLM capabilities.
Hidden Risks in Ignoring LLM Deprecation
Ignoring LLM deprecations rarely results in immediate system failure; instead, issues emerge gradually. For instance, output quality may decline, formatting inconsistencies may appear, and latency may increase over time. Therefore, these problems often go unnoticed until they affect end users.
Moreover, cost structures may change without clear visibility, leading to unexpected increases in operational expenses. In complex environments such as product engineering, these inefficiencies can compound quickly. As a result, failing to address LLM lifecycle changes introduces hidden technical debt. Over time, this debt reduces system reliability, increases maintenance effort, and limits the ability to scale effectively.
What Actually Breaks When an LLM Changes
Although newer LLM versions promise improved capabilities, they often introduce subtle but impactful inconsistencies. As a result, systems rarely fail outright; instead, they degrade in ways that are harder to detect and diagnose. Moreover, many applications rely on implicit assumptions about how an LLM behaves. When these assumptions no longer hold, outputs may still appear valid while being contextually incorrect. Therefore, identifying these failures requires deeper validation beyond surface-level checks.
Additionally, applications built without robust testing frameworks are especially vulnerable. In systems where LLM outputs drive downstream processes, even minor deviations can propagate into larger issues. Consequently, understanding what breaks during LLM transitions is essential for building resilient and maintainable systems.
Prompt Drift and Behavioral Variability
One of the most common issues is prompt drift, where the same input produces different outputs across LLM versions. Even when prompts remain unchanged, variations in reasoning patterns can significantly alter results. Moreover, these differences are often subtle, making them difficult to detect during initial testing. Therefore, systems may appear functional while delivering degraded performance.
As a result, prompt stability cannot be assumed. Teams must continuously validate and refine prompts to ensure consistent behavior across evolving LLM environments.
Output Format and Schema Inconsistencies
Structured outputs are critical for many applications; however, LLM updates often introduce formatting inconsistencies. Consequently, even small deviations can break pipelines that rely on strict schemas.Moreover, systems without proper validation mechanisms may fail silently. Therefore, debugging becomes more complex, especially in large-scale deployments.
In environments supported by quality assurance and testing, maintaining output consistency becomes a central requirement. As a result, enforcing strict validation rules is essential for reliable system behavior.
Latency and Cost Fluctuations
As LLM architectures evolve, performance characteristics such as latency and token usage also change. Consequently, applications may experience slower response times or increased costs without any code modifications.
Moreover, these changes often emerge gradually, making them difficult to attribute directly to the LLM. Therefore, teams must actively monitor performance metrics to identify anomalies. Additionally, in high-scale systems, even small inefficiencies can significantly impact overall costs. As a result, maintaining continuous performance visibility is critical for sustainable LLM operations.
Why Simple LLM Migration Strategies Fail
At first glance, replacing one LLM with another seems simple; however, real systems rarely behave that way. Instead, most applications contain deeply embedded dependencies tied to specific model behaviors. Therefore, even small differences between models can cause unexpected output variations.
Moreover, prompts, workflows, and downstream logic are often optimized for a single LLM. As a result, migration introduces inconsistencies that are difficult to debug. Consequently, teams must approach LLM migration as a system-level transformation rather than a quick replacement task.
Model-Specific Prompt Engineering Dependencies
Prompts are typically optimized for how a specific LLM interprets instructions. Therefore, when switching models, the same prompt may produce inconsistent or degraded outputs. Moreover, differences in reasoning styles often lead to subtle but impactful changes.
As a result, teams cannot rely on previous prompt performance. Instead, prompts must be re-evaluated and iteratively refined. Consequently, prompt engineering becomes an ongoing process that evolves alongside the LLM rather than remaining static.
Tokenization and Context Window Differences
Different LLMs process text using distinct tokenization strategies. Therefore, identical inputs may result in varying token counts and outputs. Moreover, context window limits differ, which affects how much information is retained during processing.
As a result, longer inputs may be truncated or interpreted differently. Consequently, systems must adapt dynamically to these constraints. Rather than assuming uniform behavior, teams should design workflows that remain flexible across varying LLM configurations.
Implicit Assumptions in Existing Pipelines
Many LLM-based pipelines rely on assumptions about output consistency and structure. However, these assumptions are rarely documented, which makes them difficult to identify. Therefore, when models change, these hidden dependencies often cause failures.
Moreover, downstream systems expect predictable outputs, and even minor deviations can break workflows. As a result, teams must explicitly define and validate these assumptions. Consequently, removing hidden dependencies improves system resilience during LLM transitions.
Core Principles for Building Future-Proof LLM Systems
To handle continuous change, teams must design systems that are independent of specific LLM implementations. Instead of building tightly coupled integrations, flexible architectures should be prioritized. Therefore, systems can adapt without major disruptions when models evolve.
Moreover, this approach improves control over cost, performance, and reliability. As a result, organizations reduce dependency on a single provider. Consequently, future-proof systems focus on adaptability, monitoring, and evaluation rather than static configurations.
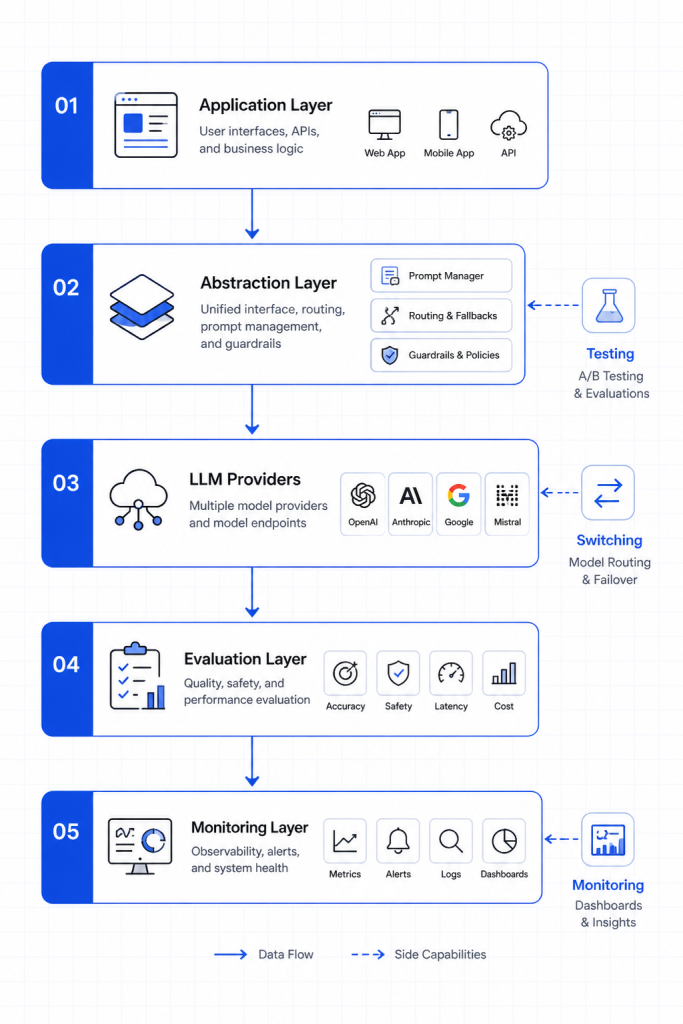
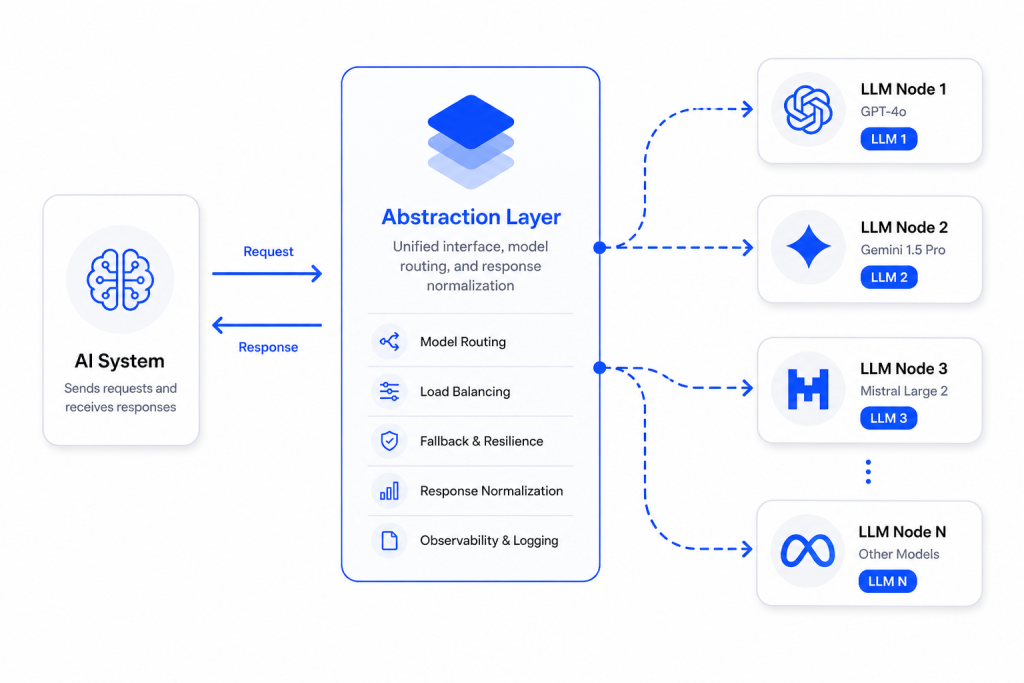
Designing a Model-Agnostic Abstraction Layer
A model-agnostic abstraction layer separates application logic from LLM-specific APIs. Therefore, switching between models becomes easier without rewriting core functionality. Moreover, it reduces vendor lock-in and improves long-term flexibility.
In scalable environments such as software development solutions, this design is essential. As a result, teams can experiment with different models efficiently. Consequently, abstraction layers form the foundation of resilient LLM systems.
Enabling Dynamic Model Switching
Dynamic model switching allows systems to choose different LLMs based on performance or cost requirements. Therefore, applications can adapt to changing conditions without manual intervention. Moreover, fallback mechanisms ensure continuity during outages.
As a result, system reliability improves significantly. Instead of relying on a single provider, teams gain operational flexibility. Consequently, dynamic switching transforms LLM usage into a strategic advantage.
Establishing Robust Evaluation Pipelines
Evaluation pipelines ensure that outputs remain consistent across LLM updates. Therefore, comparing responses against benchmarks helps detect regressions early. Moreover, automated testing reduces reliance on manual validation.
As a result, teams can maintain quality at scale. Continuous evaluation provides confidence during migrations. Consequently, these pipelines become essential for maintaining reliable LLM-driven systems.
Monitoring Cost, Latency, and Output Quality
Continuous monitoring provides visibility into system performance. Therefore, teams can quickly identify anomalies in cost, latency, or output quality. Moreover, this visibility supports proactive optimization.
As a result, operational efficiency improves over time. Monitoring ensures that systems remain stable under changing conditions. Consequently, it becomes a core component of any LLM infrastructure.
Integrating AI Governance and Data Controls
AI governance ensures that systems remain compliant and traceable. Therefore, teams can monitor how data is used and how outputs are generated. Moreover, governance frameworks help manage risks associated with evolving models.
As a result, systems maintain both technical and operational stability. Proper controls improve accountability and transparency. Consequently, governance becomes critical for long-term LLM sustainability.
A Practical LLM Migration Workflow
A structured workflow simplifies LLM migration by breaking it into controlled steps. Instead of making abrupt changes, teams can transition gradually while maintaining system stability. Therefore, risks are minimized and performance remains consistent.
Moreover, this approach ensures decisions are data-driven. As a result, teams gain better visibility into system behavior during migration. Consequently, structured workflows transform LLM migration into a manageable process.
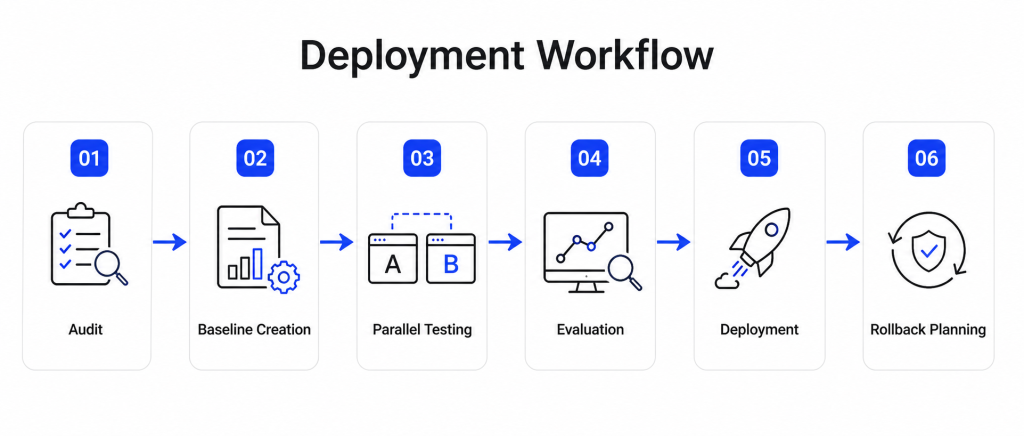
Auditing Current LLM Usage
The first step is identifying where and how the LLM is used across the system. Therefore, teams must map prompts, workflows, and dependencies. Moreover, this helps highlight critical areas that require careful handling.
- Map all LLM touchpoints
- Identify high-impact workflows
- Highlight risk-prone components
As a result, teams gain clarity on system dependencies. Consequently, this step forms the foundation for a successful migration strategy.
Creating Test Cases and Baselines
Defining baselines allows teams to measure output consistency during migration. Therefore, expected responses must be documented clearly. Moreover, test cases should represent real-world usage scenarios.
- Create input-output test cases
- Define acceptable performance thresholds
- Store baseline outputs
As a result, teams can compare performance accurately. Consequently, this ensures that new LLMs meet required standards before deployment.
Running Parallel Model Evaluations
Running models in parallel allows teams to compare outputs effectively. Therefore, differences in accuracy, cost, and latency can be analyzed. Moreover, this reduces uncertainty during migration decisions.
- Compare outputs across models
- Measure performance metrics
- Identify strengths and weaknesses
As a result, teams can make informed decisions. Consequently, this step reduces the risk of adopting unsuitable LLMs.
Gradual Deployment and Rollback Planning
Gradual deployment ensures that migration does not disrupt production systems. Therefore, updates should be rolled out in controlled phases. Moreover, rollback mechanisms provide safety in case of failures.
- Deploy in incremental stages
- Monitor system performance
- Maintain rollback strategies
As a result, teams maintain operational stability. Consequently, phased deployment ensures smooth LLM transitions without major disruptions.
Common Pitfalls in LLM Migration Projects
Even with a structured approach, LLM migration projects often fail due to avoidable mistakes. While teams focus on upgrading models, they frequently overlook system-level dependencies and operational risks. Therefore, issues arise not from the LLM itself but from how it is integrated and managed.
Moreover, many of these pitfalls stem from incorrect assumptions about stability and performance. As a result, systems become fragile and harder to maintain over time. Consequently, recognizing these patterns early allows teams to reduce risk, improve reliability, and ensure smoother transitions across evolving LLM environments.
Over-Reliance on a Single LLM Provider
Relying on a single LLM provider creates a critical dependency that limits flexibility. Therefore, when models change or are deprecated, systems face immediate disruption. Moreover, this dependency increases exposure to cost fluctuations and performance variability.
As a result, teams lose control over their own infrastructure decisions. Instead, they are forced to react to external changes. Consequently, diversifying across multiple LLMs improves resilience and ensures continuity during unexpected transitions.
Ignoring Regression Testing
Regression testing is often overlooked in LLM migration projects, especially when outputs appear superficially correct. However, subtle deviations can accumulate and affect system behavior over time. Therefore, relying on manual checks is insufficient.
Moreover, without structured validation, errors may reach production unnoticed. As a result, user experience degrades while debugging becomes more complex. Consequently, consistent regression testing is essential to maintain output quality and system reliability.
Optimizing for Benchmarks Instead of Stability
Teams often prioritize benchmark performance when selecting an LLM. However, real-world conditions differ significantly from controlled evaluations. Therefore, a model that performs well in benchmarks may fail under production constraints.
Moreover, excessive optimization can introduce fragility into the system. As a result, small changes in input or context may lead to inconsistent outputs. Consequently, focusing on stability and reliability ensures long-term success rather than short-term performance gains.
Final Thoughts: Designing Beyond the LLM Itself
As LLM ecosystems continue to evolve, building systems around a single model is no longer sustainable. Instead, teams must design architectures that anticipate change and adapt continuously. Therefore, resilience becomes a core requirement rather than an optional improvement.
Moreover, shifting from a model-centric to a system-centric mindset allows organizations to maintain control over performance and reliability. As a result, they can respond effectively to evolving requirements without major disruptions. Consequently, the true value of LLM integration lies not in the model itself but in how well the surrounding system is designed to support change.
Frequently Asked Questions (FAQs)
1. What is LLM migration?
LLM migration is the process of transitioning from one model to another while ensuring output consistency, performance stability, and cost control. It involves adapting prompts, workflows, and system dependencies to align with new model behavior. Additionally, it ensures that performance benchmarks are maintained across changing LLM environments.
2. Why do LLM-based systems break over time?
They break because LLMs evolve continuously, which changes output behavior, cost structure, and performance characteristics. Even without visible updates, internal model adjustments can affect how prompts are interpreted.As a result, systems relying on static assumptions become unstable over time.
3. How can I future-proof my LLM application?
You can future-proof it by using abstraction layers, dynamic model switching, and continuous evaluation pipelines. These approaches reduce dependency on a single model and improve adaptability. Moreover, consistent monitoring ensures long-term stability and performance.
4. What is prompt drift in LLM systems?
Prompt drift occurs when the same input prompt produces different outputs due to changes in LLM behavior. This can affect accuracy, tone, and formatting in subtle ways. Therefore, continuous validation is required to maintain consistent results.
5. Is testing necessary during LLM migration?
Yes, testing is critical to detect regressions, maintain output quality, and ensure stable system performance. Without testing, silent failures can reach production unnoticed. Consequently, structured validation becomes essential for reliable LLM integration.



