

Why Platform Engineering Is Now a Structural Imperative
As software ecosystems expand, Platform Engineering has become a critical foundation for sustainable and scalable operations. Initially, DevOps improved collaboration and delivery speed, yet growing complexity across cloud environments, microservices, and multi-team deployments has revealed operational weaknesses. Consequently, organizations face fragmented workflows, inconsistent infrastructure, and hidden risks that slow feature releases and increase developer fatigue.
Therefore, Platform Engineering emerges not merely as a set of tools but as a strategic framework that standardizes infrastructure, automates governance, and reduces cognitive load for engineers. By implementing internal developer platforms and repeatable workflow patterns, companies can maintain speed without compromising reliability. Over time, this approach enables predictable delivery, reduces risk, and forms a foundation for modern digital transformation initiatives across software development, web development, and product engineering teams.
What Platform Engineering Fundamentally Re-Architects
While DevOps improved collaboration, it did not formalize infrastructure as a durable internal capability. Consequently, many organizations still depend on fragmented scripts, undocumented conventions, and loosely governed cloud environments. As scale increases, those informal systems become harder to sustain.
Therefore, platform engineering re-architects delivery by transforming infrastructure into a productized internal platform. Instead of treating automation as scattered tooling, it establishes curated services, reusable workflows, and embedded governance models. Moreover, architectural decisions are standardized without eliminating autonomy. As a result, engineering teams operate within structured boundaries that reduce operational risk while maintaining delivery velocity.
Internal Developer Platforms as Long-Term Assets
An internal developer platform consolidates provisioning, deployment logic, and access management into a unified interface. Although backend complexity remains significant, it is intentionally abstracted behind reusable services. Consequently, developers interact with consistent workflows rather than raw infrastructure layers.
Platform engineering treats this system as a living internal product rather than a static framework. Therefore, documentation, usability, and feedback loops are prioritized. Because platform evolution is measured continuously, improvements become deliberate rather than reactive. Over time, infrastructure access becomes predictable, reducing friction across distributed engineering environments.
Golden Paths and Opinionated Standards
Golden paths define recommended architectural blueprints for recurring workloads. While flexibility remains available, preferred patterns reduce unnecessary experimentation at the infrastructure layer. Consequently, architectural variability declines without suppressing innovation.
Through platform engineering, these standards are collaboratively defined instead of being imposed centrally. Therefore, cross-team alignment strengthens and duplicated solutions decrease. Because templates are version-controlled and iteratively refined, enhancements propagate consistently. Over time, architectural coherence improves and operational surprises are significantly reduced.
Governance Embedded Through Automation
Traditional governance models rely heavily on manual reviews and late-stage compliance checks. However, as system complexity increases, reactive oversight becomes insufficient. Consequently, risk often surfaces only after deployment, when remediation is costly.
Platform engineering embeds policy as code directly into delivery pipelines. Therefore, security, compliance, and cost controls are enforced automatically rather than audited retrospectively. Because governance rules are codified and version-controlled, enforcement remains consistent across environments. Over time, operational risk exposure decreases while development speed remains stable.
The Core Pillars of Sustainable Platform Engineering
Sustainable platform engineering depends on structural clarity rather than tooling accumulation. Although automation accelerates delivery, long-term stability emerges only when architectural boundaries are clearly defined. Consequently, scalable environments require discipline that balances autonomy with governance.
Moreover, resilience improves when provisioning, compliance, and monitoring operate as interconnected capabilities. Therefore, mature platform ecosystems are anchored in self-service infrastructure, codified environments, and continuous observability. These pillars do not function independently; instead, they reinforce one another through structured feedback loops. As a result, operational maturity strengthens gradually, and systemic risk is reduced before it compounds across distributed systems.
Self-Service Infrastructure With Guardrails
Self-service provisioning allows developers to deploy resources without prolonged approval cycles. However, autonomy without boundaries can introduce instability. Consequently, guardrails must be embedded directly into workflows rather than applied retroactively.
Platform engineering enables controlled self-service models in which approved templates guide safe provisioning. Instead of exposing unrestricted cloud parameters, curated configurations enforce security and cost policies automatically. Therefore, delivery speed increases while compliance integrity is preserved. Because constraints are predefined and transparent, developers operate confidently within structured limits. Over time, operational bottlenecks decline and infrastructure reliability improves.
Infrastructure as Code and Policy as Code
Infrastructure defined through code ensures repeatability across staging and production environments. Although manual configuration once dominated operations, it often introduced hidden inconsistencies. Consequently, environment drift became difficult to detect.
Through platform engineering, infrastructure as code and policy as code become foundational practices rather than optional enhancements. Therefore, configuration standards are version-controlled and audited systematically. Because changes are reviewed like application logic, transparency improves across teams. Over time, repeatable deployments strengthen operational predictability while reducing risk exposure.
Observability and Continuous Feedback Loops
Observability transforms monitoring from reactive alerting into structured insight generation. While logs capture failures, they rarely explain systemic inefficiencies. Consequently, recurring weaknesses may remain unaddressed.
Platform engineering integrates centralized telemetry and traceability directly into platform defaults. Therefore, performance metrics and anomaly detection operate continuously rather than sporadically. Because feedback loops are automated, deviations are identified earlier and resolved faster. Over time, engineering decisions become evidence-driven, strengthening long-term system resilience.
A Phased Blueprint for Implementing Platform Engineering
Platform engineering adoption requires deliberate sequencing rather than abrupt transformation. Although modernization initiatives often begin with enthusiasm, unstructured rollouts introduce unnecessary disruption. Consequently, phased implementation improves adoption and reduces resistance.
Moreover, leadership alignment must accompany architectural redesign. Therefore, transformation typically progresses through diagnosis, intentional platform design, and incremental rollout. Each stage builds institutional confidence while minimizing operational risk. As organizations refine delivery models across custom software development, this structured approach ensures that platform engineering becomes a sustainable capability rather than a short-lived initiative.
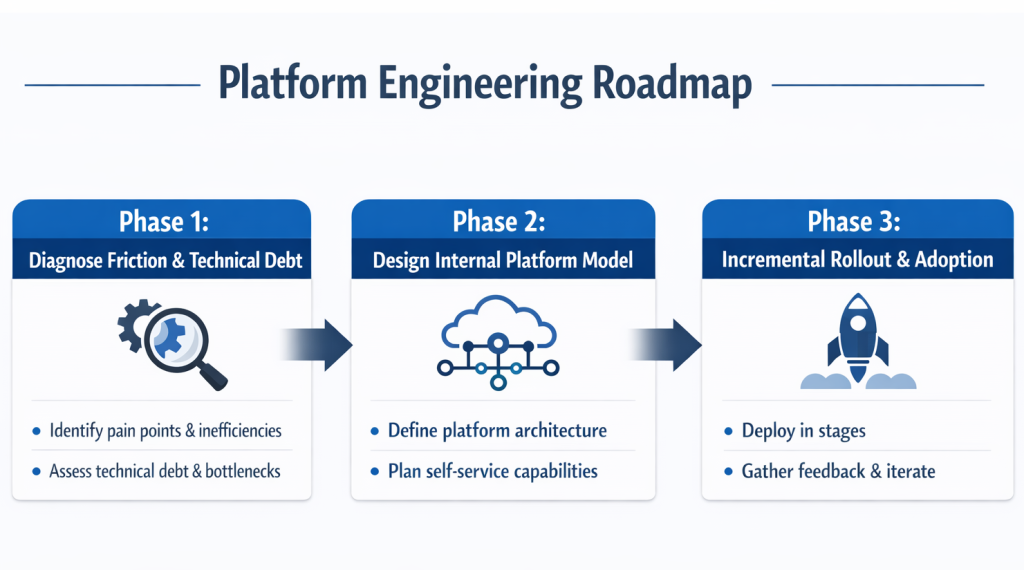
Phase One – Diagnose Friction and Technical Debt
The initial phase focuses on identifying workflow bottlenecks, duplicated tooling, and governance gaps. Although inefficiencies may appear isolated, their causes are frequently systemic. Consequently, cross-functional assessments are necessary to uncover structural weaknesses.
Platform engineering begins by establishing measurable baselines such as deployment frequency, rollback rates, and infrastructure costs. Therefore, priorities are determined by impact rather than assumption. Because transformation decisions are evidence-based, stakeholder confidence increases. Over time, clarity replaces ambiguity and redesign efforts become more targeted.
Phase Two – Design the Internal Platform Model
Once friction points are identified, architectural standards and automation layers must be defined deliberately. While flexibility remains essential, boundaries must be clarified to prevent future variability. Consequently, reusable templates and curated service catalogs are structured around recurring workloads.
Platform engineering emphasizes usability, governance alignment, and developer experience during this phase. Therefore, compliance and productivity are balanced intentionally. Because feedback mechanisms are introduced early, adoption barriers are reduced. Over time, the internal platform evolves cohesively instead of fragmenting into disconnected scripts.
Phase Three – Incremental Rollout and Measurable Adoption
Abrupt, organization-wide rollouts often generate resistance and instability. Instead, controlled onboarding fosters trust and refinement. Consequently, early adopters validate workflows before expansion occurs.
Platform engineering teams monitor provisioning times, deployment stability, and usage metrics during rollout. Therefore, refinements are introduced iteratively rather than reactively. Because transparency is maintained, cross-team confidence strengthens. Over time, adoption expands organically, reinforcing structural discipline without cultural friction.
Measuring the Executive Impact of Platform Engineering
Platform engineering delivers measurable outcomes that resonate with leadership priorities. Although technical improvements are valuable, executive stakeholders require visibility into metrics such as deployment speed, cost efficiency, and risk mitigation. Consequently, structured internal platforms link engineering practices to tangible business impact.
By standardizing workflows, automating compliance, and embedding observability, platform engineering reduces operational friction and enhances decision-making. Therefore, organizations can confidently scale web, mobile, and backend systems while maintaining predictability. Furthermore, transparent performance metrics allow executives to monitor delivery velocity, resource utilization, and developer satisfaction. Over time, these measurable improvements support strategic planning, reduce operational surprises, and strengthen investment in scalable internal platforms across ongoing digital transformation initiatives
Accelerated Release Cycles and Reduced Lead Time
Standardization of infrastructure and workflows directly improves deployment predictability. While manual processes introduce delays, structured platforms streamline provisioning and testing. Consequently, lead times shrink and release frequency increases.
Platform engineering ensures repeatable, codified deployment paths, enabling teams to focus on high-value tasks instead of firefighting. Therefore, development cycles are shorter, rollback risks decrease, and velocity is consistently measurable. Because early-stage inefficiencies are addressed proactively, engineering teams gain confidence in delivery, ultimately improving organizational responsiveness across software development projects.
Cloud Cost Optimization and Resource Visibility
Uncontrolled cloud provisioning often drives wasted resources and unnecessary expenditure. Although cloud scaling is critical, lack of oversight reduces operational efficiency. Consequently, financial risk rises as system complexity grows.
Through platform engineering, centralized provisioning and cost-aware defaults provide visibility into resource consumption. Therefore, redundant infrastructure is eliminated and budget adherence improves. Because provisioning and usage are continuously monitored, cloud spending is optimized without sacrificing performance. Over time, these practices reinforce fiscal discipline while sustaining engineering agility across multi-cloud and hybrid environments.
Improved Developer Experience and Retention
High cognitive load and unclear workflows undermine developer productivity and morale. Although compensation and culture are important, daily operational clarity strongly influences retention. Consequently, turnover risks rise when engineers face persistent friction.
Platform engineering reduces unnecessary complexity and provides self-service infrastructure alongside structured feedback loops. Therefore, developers focus on innovation rather than troubleshooting. Because autonomy is preserved within clearly defined boundaries, engagement and satisfaction increase. Over time, organizations benefit from stronger institutional knowledge, higher retention, and more reliable software delivery.
Common Misconceptions That Delay Platform Engineering
Despite clear advantages, platform engineering adoption is often delayed due to misunderstandings about scope and necessity. Although some assume it is merely a rebranding of DevOps, structural differences are significant. Consequently, organizations may postpone investment until scaling problems become urgent.
Moreover, misconceptions about cost, complexity, or applicability to smaller teams can prevent early adoption. Platform engineering requires strategic intent and deliberate design rather than impulsive tool selection. Therefore, clarifying purpose and expected outcomes early ensures alignment with business objectives. Over time, early investment reduces technical debt, accelerates delivery, and establishes internal platforms as a sustainable capability across web development, mobile apps, and product engineering teams.

“Platform Engineering Is Just DevOps Rebranded”
While DevOps emphasizes collaboration and cultural change, platform engineering institutionalizes infrastructure as a product. Although related, DevOps lacks codified internal platforms, automated guardrails, and standardized workflows. Consequently, teams attempting to scale without formal platforms encounter friction and drift.
Platform engineering defines reusable workflows, curated templates, and embedded compliance, transforming infrastructure management into a predictable system. Therefore, it provides structured decision-making while preserving developer autonomy. Because repeatable patterns replace ad hoc practices, velocity and reliability improve. Over time, scaling becomes deliberate and less error-prone, differentiating platform engineering clearly from traditional DevOps practices.
“Only Large Enterprises Need Platform Engineering”
Many organizations assume that platform engineering is relevant only for large enterprises. However, mid-sized and growing companies face scaling challenges that are equally disruptive. Consequently, delaying adoption can result in duplicated tooling, fragmented workflows, and escalating operational risk.
Implementing platform engineering early introduces structured governance, codified environments, and self-service layers before complexity becomes unmanageable. Therefore, even smaller teams benefit from predictable deployments and reduced cognitive load. Because patterns and guardrails are embedded from the outset, adoption is smoother and risk is lower. Over time, early implementation creates a foundation for scalable engineering growth and more reliable delivery across all digital initiatives.
Conclusion: Platform Engineering as the Foundation of Digital Resilience
As cloud-native systems and distributed architectures continue to evolve, platform engineering has become a foundational operating model rather than an optional optimization. While DevOps drove initial cultural change, the complexity of modern software delivery now demands formalized internal platforms. Consequently, organizations that implement platform engineering experience predictable delivery, improved operational stability, and a more sustainable developer experience.
By integrating automation, observability, and codified infrastructure, teams reduce cognitive load and focus on innovation rather than repetitive operational tasks. Because workflows are repeatable and governance is embedded, risk exposure decreases while velocity increases. Over time, platform engineering strengthens system resilience, enables scalable growth, and positions organizations for long-term success in delivering high-quality software across diverse digital initiatives.
Frequently Asked Question (FAQs)
1. What is platform engineering in simple terms?
Platform engineering is the practice of creating structured internal platforms that provide developers with standardized tools, workflows, and environments. These platforms reduce manual setup, enforce governance, and automate repetitive tasks, allowing engineering teams to focus on building features efficiently while minimizing errors and operational friction.
2. How is platform engineering different from DevOps?
DevOps emphasizes cultural collaboration and continuous delivery practices, but it does not always formalize infrastructure or governance. Platform engineering builds on DevOps by productizing internal platforms, codifying workflows, and embedding compliance directly into delivery pipelines, creating a scalable, repeatable, and reliable system for engineering teams.
3. When should a company adopt platform engineering?
A company should adopt platform engineering when scaling introduces tool sprawl, inconsistent environments, or repeated operational bottlenecks. It is particularly valuable for teams experiencing high cognitive load, frequent deployment failures, or difficulties in maintaining consistent infrastructure across projects. Early adoption ensures smoother scaling and long-term system reliability.
4. Can platform engineering reduce cloud costs?
Yes, platform engineering reduces cloud costs by providing centralized provisioning, standardized templates, and automated policy enforcement. These practices eliminate duplicate resources, prevent unnecessary spending, and ensure optimal use of infrastructure. Over time, organizations gain better visibility into consumption and can forecast costs more accurately while maintaining system performance.
5. Is platform engineering suitable for startups and mid-sized companies?
Absolutely. Startups and mid-sized companies often face rapid growth and increasing system complexity. Implementing platform engineering early provides structured governance, repeatable workflows, and predictable infrastructure management, which reduces operational risk and prevents technical debt. This approach ensures that teams can scale efficiently without losing velocity or quality in software delivery.



