

Introduction: The Rising Importance of RAG in Intelligent Systems
In today’s evolving digital landscape, RAG (Retrieval-Augmented Generation) is reshaping how intelligent systems think, learn, and deliver results. As enterprises strive for greater accuracy and speed, RAG allows them to merge real-time data retrieval with the creative reasoning of large language models. This combination ensures that AI outputs remain both innovative and grounded in reliable, current information.
Furthermore, since traditional AI models often generate outdated or context-limited responses, RAG fills this critical void. It empowers teams to build systems that retrieve knowledge dynamically while generating insightful, human-like outputs. As a result, organizations investing in AI and Machine Learning or Custom Software Development are increasingly prioritizing RAG-based architectures to stay ahead.
Ultimately, RAG enhances decision-making, strengthens data reliability, and enables AI ecosystems to evolve continuously—making it a transformative force in modern intelligent applications.
Understanding RAG: The Smart Bridge Between Retrieval and Generation
As businesses increasingly rely on AI for critical operations, RAG (Retrieval-Augmented Generation) emerges as a breakthrough that bridges two essential capabilities — retrieving relevant information and generating intelligent responses. Unlike conventional AI systems that rely solely on pre-trained data, RAG dynamically accesses external sources in real time, ensuring that every answer remains contextually accurate and up to date.
Therefore, RAG acts as a strategic connector between structured databases and generative reasoning, allowing organizations to deploy solutions that respond intelligently to evolving user needs. This dual mechanism not only improves precision but also strengthens trust in AI-driven decisions. Moreover, companies already utilizing AI employees or predictive tools can enhance those systems by embedding RAG pipelines for more context-aware interactions.
Through this integration, RAG transforms how enterprises use AI—turning static models into adaptive, knowledge-rich assistants capable of delivering meaningful insights across diverse industries.
How RAG Works Behind the Scenes
To understand RAG’s strength, it’s essential to explore how it functions beneath the surface. The process begins with retrieval, where the system searches large data repositories to find relevant content. Next comes augmentation, which enhances retrieved data by embedding context before passing it to the generative model. The generation stage then creates responses that combine factual accuracy with natural expression. Finally, through refinement, the model evaluates its output for consistency and relevance.
Consequently, this four-step loop ensures that every output is both informed and coherent. Businesses implementing AI & Machine Learning solutions benefit immensely from this structure, as it maintains balance between performance and scalability while ensuring accuracy under real-world conditions.
Why RAG Beats Traditional AI Models
Traditional AI models depend heavily on static training data, which quickly becomes outdated. In contrast, RAG integrates continuous retrieval, allowing systems to access new information as it becomes available. As a result, AI responses remain relevant, factual, and aligned with recent developments.
Moreover, RAG reduces the need for frequent retraining—saving time, resources, and operational costs. It delivers enhanced transparency by clearly showing where data originates, an advantage that traditional LLMs lack. In industries where data integrity and compliance are vital, such as finance or healthcare, RAG ensures that decision-making remains grounded in verifiable knowledge.
Ultimately, this dynamic combination of retrieval and reasoning gives RAG a distinct edge, enabling companies to scale intelligence confidently while maintaining control over accuracy and data trustworthiness.
RAG Integration Process: From Blueprint to Deployment
Integrating RAG into business systems requires a clear, well-structured roadmap. Since every stage builds upon the previous one, a systematic approach ensures accuracy, speed, and long-term scalability. The process typically begins with preparing high-quality data, followed by creating the retrieval pipeline and connecting it with generative components. This ensures that both structured and unstructured information flow seamlessly within the system.
Moreover, because every organization’s goals differ, the integration must remain flexible enough to evolve with time. Therefore, a step-by-step deployment approach allows teams to test, adapt, and optimize efficiently. Ultimately, RAG integration empowers enterprises to align AI capabilities with business intelligence—transforming raw data into actionable, context-rich insights that drive smarter decisions.
Preparing the Right Data Foundation
A successful RAG implementation starts with a reliable data foundation. Clean, organized, and diverse datasets improve retrieval accuracy and ensure meaningful results. Consequently, data engineers must identify trustworthy sources, remove redundancy, and structure information for quick indexing.
In addition, embedding techniques such as vectorization help systems interpret semantic relationships between data points. By understanding context rather than keywords alone, the retrieval layer becomes far more accurate. Therefore, companies that prioritize data quality experience fewer inconsistencies and more reliable model performance. Ultimately, structured preparation transforms unrefined data into a powerful base for real-time retrieval and dynamic AI reasoning.
Building the Retrieval and Augmentation Pipeline
Once data is ready, the next step is constructing the retrieval and augmentation pipeline. This phase defines how information is stored, accessed, and connected with the AI model. The process begins by embedding data into a vector database, where semantic search enables relevant content discovery. Subsequently, augmentation integrates retrieved information with model prompts, ensuring factual precision and context balance.
As a result, AI responses become both human-like and data-driven. Furthermore, optimizing the pipeline for latency and scalability is crucial for enterprises handling large datasets. Through this well-designed pipeline, RAG systems achieve faster results while preserving the integrity of their knowledge base.
Model Integration, Testing, and Optimization
After the retrieval pipeline is built, the final step involves model integration and continuous refinement. Developers connect the retrieval mechanism to the generative layer, ensuring that context flows seamlessly from one stage to another. Testing then measures accuracy, relevance, and consistency of outputs under various scenarios.
Moreover, feedback loops play a critical role in fine-tuning performance. As users interact with the system, their inputs guide adjustments that enhance both response quality and speed. Consequently, this cyclical optimization ensures that RAG-based systems remain reliable, adaptable, and aligned with evolving business objectives.
The Real Cost Breakdown of RAG Integration
Understanding the true cost of RAG integration is vital before implementation begins. While many organizations focus on initial setup, the ongoing expenses often shape the total investment. Therefore, a transparent cost breakdown helps decision-makers plan realistically and optimize long-term returns.
In most cases, total RAG expenses can be grouped into three categories: setup, operational maintenance, and scalability. Each depends on the organization’s data volume, technology stack, and complexity. The following table gives an overview of typical RAG cost components and how they affect overall spending:
| Cost Category | Key Components | Impact on Total Cost |
| Setup Costs | Data preparation, embeddings, infrastructure setup | High at start; one-time investment |
| Operational Costs | LLM API usage, storage, maintenance, monitoring | Ongoing; varies with usage volume |
| Scalability Costs | Compute power, optimization, advanced integrations | Increases as data and users grow |
Therefore, businesses that plan resource allocation early often avoid unforeseen cost escalations while achieving more predictable project timelines.
Setup Costs and Infrastructure Planning
The foundation of any RAG project lies in its setup. Initial costs include preparing clean data, generating embeddings, and configuring the retrieval database. Additionally, companies must account for compute resources, developer time, and integration frameworks.
To manage these expenses efficiently:
- Choose scalable cloud infrastructure instead of on-premise servers.
- Reuse existing data pipelines where possible.
- Invest in modular components for easy updates.
Since these costs are typically one-time, thoughtful planning can significantly lower future expenses. Hence, proper setup ensures stability and smooth integration during later development stages.
Ongoing Maintenance and Optimization Costs
While setup marks the beginning, maintenance and optimization determine long-term success. These recurring costs include LLM query usage, database upkeep, and continuous performance tuning. Over time, they form the bulk of an organization’s operational budget.
To reduce recurring expenses:
- Monitor query patterns to identify redundant operations.
- Use caching for frequently accessed data.
- Apply automation for version control and fine-tuning tasks.
Therefore, consistent optimization not only minimizes cost but also sustains response speed and output quality—ensuring that RAG systems remain efficient as data grows.
How Cost Varies by Project Scale and Industry
Every industry faces unique financial dynamics when adopting RAG solutions. For instance, real estate and healthcare handle vast, complex data requiring advanced infrastructure, while smaller startups can rely on open-source options.
Typical cost ranges (approximate estimates):
| Organization Type | Estimated Initial Cost (USD) | Ongoing Monthly Cost (USD) |
| Small Startup | $10,000–$25,000 | $1,000–$2,500 |
| Mid-Size Enterprise | $40,000–$80,000 | $3,000–$6,000 |
| Large Enterprise | $100,000+ | $10,000+ |
Consequently, organizations must align their RAG budget with data volume, regulatory standards, and scaling goals. Proper planning enables teams to invest intelligently while maximizing long-term returns.
Challenges in RAG Integration and Smart Solutions
Although RAG integration offers remarkable advantages, it also presents several practical challenges. Many organizations struggle with balancing accuracy, cost, and scalability, especially when handling complex data environments. Therefore, identifying these issues early allows teams to take corrective action before they affect system performance.
The most frequent obstacles include technical errors, skill shortages, security risks, and scalability constraints. Each of these can slow deployment or reduce overall efficiency if left unaddressed. However, with proper planning, monitoring, and iterative improvement, businesses can overcome these barriers and ensure their RAG systems remain reliable and sustainable over time.
Handling Technical Barriers and Data Issues
Technical challenges often emerge during the initial stages of RAG integration. Unstructured data, inconsistent embeddings, or incompatible infrastructure can impact retrieval accuracy. Therefore, establishing data standards and robust pipelines becomes essential to system reliability.
To resolve these issues:
- Conduct detailed data audits before integration.
- Maintain consistent data schemas across all sources.
- Monitor embeddings for drift and update periodically.
By addressing these aspects proactively, teams improve data alignment and ensure that retrieval models perform efficiently across multiple information sources.
Managing Team Skills and Budget Constraints
RAG development requires a blend of AI engineering, data science, and infrastructure expertise. However, many teams either lack such skill diversity or face budget limitations. Consequently, implementation slows down or quality declines when internal capacity is stretched.
To balance resources:
- Upskill current staff through AI and ML workshops.
- Collaborate with external experts during key milestones.
- Distribute responsibilities strategically across departments.
This balanced approach enhances productivity while keeping budgets manageable—ensuring steady project progress without unnecessary delays.
Ensuring Data Security and Compliance
Since RAG operates on sensitive and wide-ranging data, maintaining security and compliance is non-negotiable. Organizations must therefore safeguard retrieved content while adhering to regional privacy laws.
Recommended practices include:
- Applying end-to-end encryption for stored and retrieved data.
- Establishing access control policies to protect sensitive sources.
- Conducting routine security audits and updates.
Through these measures, enterprises build trust and ensure that their AI ecosystems operate ethically and securely within regulatory boundaries.
Maintaining Consistency and Scalability
As data volumes and model usage expand, sustaining system speed and quality becomes challenging. Without careful optimization, scalability issues can result in latency and inconsistent responses.
To maintain balance:
- Develop modular system architectures for flexible scaling.
- Use load balancing to manage retrieval traffic effectively.
- Implement performance monitoring for real-time system insights.
Therefore, by continuously optimizing system performance, organizations preserve reliability even as RAG integration scales with business growth.
Practical Strategies for Cost-Effective RAG Implementation
While RAG integration can transform how enterprises use AI, maintaining cost efficiency throughout the process requires strategic planning. Many teams focus on development expenses but overlook ongoing infrastructure and optimization costs. Therefore, using the right tools, approaches, and deployment methods ensures that RAG remains both powerful and affordable.
The key is to balance innovation with practicality. By combining open-source frameworks, iterative scaling, and smart infrastructure design, organizations can achieve maximum impact without overspending. Consequently, RAG adoption becomes sustainable, allowing companies to continuously evolve their AI capabilities while controlling financial overhead.
Leveraging Open-Source and Cloud Tools
Open-source and cloud-native solutions offer one of the most effective ways to lower RAG deployment costs. Instead of building every component from scratch, teams can use proven frameworks and pre-built modules.
Consider these options:
- LangChain and LlamaIndex for connecting data sources and managing context retrieval.
- FAISS or Pinecone for efficient vector database operations.
- Cloud services that scale automatically based on usage.
As a result, these tools minimize development time and reduce infrastructure demands—making RAG systems easier to maintain and expand over time.
Scaling Through Iterative Deployment
Instead of deploying a large, complex system upfront, iterative scaling allows gradual improvement through small, measurable steps. This approach ensures controlled growth and early identification of potential challenges.
Practical ways to implement this include:
- Starting with a minimum viable RAG setup before scaling.
- Continuously evaluating retrieval accuracy and performance.
- Expanding modules incrementally based on real usage data.
This strategy leads to cost savings, as organizations only invest further once the system’s value and performance are validated through consistent outcomes.
Collaborating Through Expert Augmentation Teams
Many companies lack in-house expertise for specialized RAG components. Therefore, collaborating with expert augmentation teams provides a flexible, cost-efficient solution. This model allows organizations to access skilled AI engineers, data scientists, and architects without committing to permanent hires.
Benefits include:
- Faster integration cycles and reduced training time.
- On-demand expertise for specific technical stages.
- Better project quality through focused collaboration.
Such partnerships combine flexibility with precision, ensuring complex RAG projects are completed efficiently while keeping expenses under control.
Optimizing Infrastructure for Cost and Performance
Infrastructure choices directly affect the total cost of maintaining RAG systems. Poorly configured resources or unused capacity can inflate expenses unnecessarily. Therefore, optimization must be an ongoing effort, not a one-time adjustment.
Effective strategies include:
- Automating scaling policies to match real-time workloads.
- Caching frequent retrievals to cut down on API costs.
- Monitoring resource utilization to avoid idle consumption.
By applying these principles, organizations sustain consistent RAG performance while achieving measurable cost reductions over time.
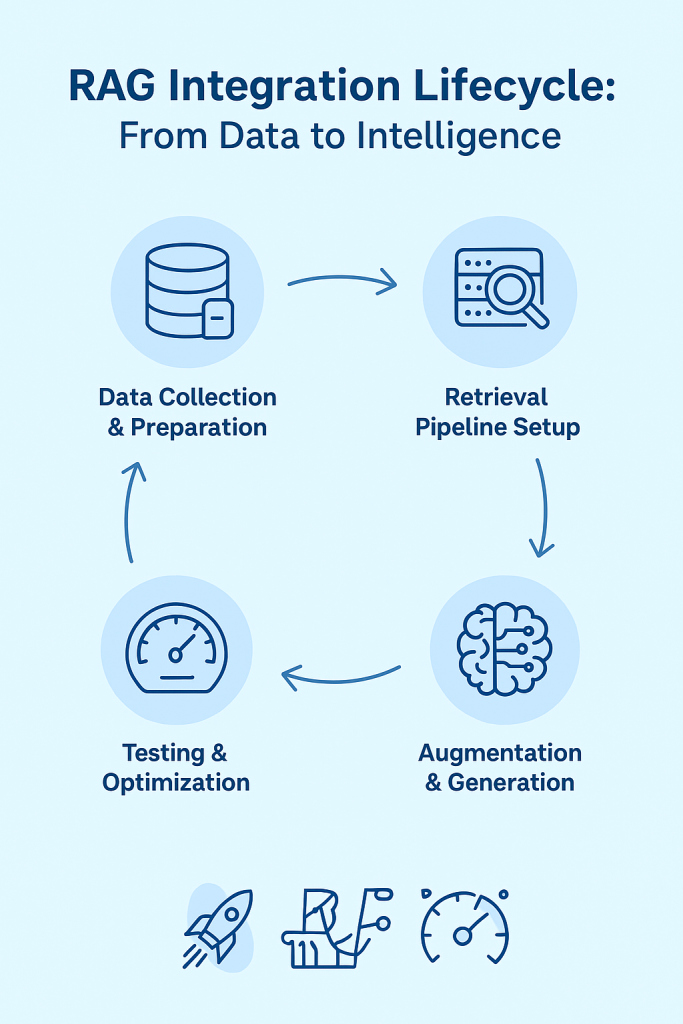
RAG Integration Lifecycle Overview
The RAG Integration Lifecycle represents the complete journey of how data transforms into intelligence through structured processes. As shown in the infographic above, each step connects seamlessly to the next, forming a continuous cycle of learning, refinement, and scalability.
It begins with Data Collection & Preparation, where information is cleaned, structured, and made retrieval-ready. The next phase, Retrieval Pipeline Setup, establishes how data will be stored and accessed through vector databases for fast, semantic search. Afterward, Augmentation & Generation allows the system to merge retrieved information with generative AI, ensuring accurate and context-rich responses.
The fourth stage, Testing & Optimization, measures response accuracy, latency, and reliability, allowing fine-tuning for peak performance. Finally, the Deployment & Scaling stage integrates the refined RAG model into production environments, where it continuously adapts and expands with real-world use.
This lifecycle shows that RAG integration is not a single-step process but an iterative evolution—each phase reinforcing data quality, cost control, and long-term system intelligence.
Conclusion: Turning RAG Integration into a Competitive Advantage
As AI technologies mature, RAG integration stands out as one of the most effective ways to combine intelligence with reliability. By merging real-time retrieval with advanced language generation, businesses can transform data into accurate, actionable insights. This synergy not only improves efficiency but also establishes long-term scalability across operations.
Moreover, organizations that embrace RAG early gain a strategic edge over competitors. Their systems evolve faster, adapt more easily, and deliver insights that remain relevant over time. Therefore, RAG isn’t just a technical upgrade—it’s a forward-looking investment in operational intelligence.
In the end, companies that view RAG integration as part of their broader digital transformation strategy will unlock measurable benefits—smarter decision-making, cost efficiency, and a foundation for future AI innovation.
Frequently Asked Questions (FAQs)
1. What is RAG integration, and why is it important?
RAG (Retrieval-Augmented Generation) combines information retrieval with generative AI to deliver more accurate and context-aware results. It’s important because it allows systems to pull from live, reliable data instead of relying solely on pre-trained knowledge, ensuring outputs stay factual, updated, and relevant.
2. How does RAG differ from traditional AI models?
Traditional AI models depend on static training data, which can quickly become outdated. In contrast, RAG systems retrieve information dynamically, allowing AI responses to stay current and precise. This integration greatly reduces data drift and enhances decision-making accuracy over time.
3. What are the main cost factors in implementing RAG?
The total cost of RAG integration depends on several variables:
- Initial setup (data preparation, embeddings, and infrastructure)
- Ongoing maintenance (LLM usage and monitoring)
- Scalability requirements (compute power and database management)
Although initial investment can be significant, efficient planning and optimization greatly reduce long-term expenses.
4. Can small and mid-sized businesses afford RAG integration?
Yes. With the availability of open-source tools and scalable cloud services, RAG is no longer limited to large enterprises. Small and mid-sized businesses can start with minimal setups, focusing on targeted use cases before expanding to full-scale integration.
5. What challenges should companies expect during RAG implementation?
Common challenges include data inconsistency, infrastructure complexity, and skill shortages. However, these can be mitigated through iterative deployment, proper data management, and strategic team collaboration. Ensuring data security and continuous optimization also plays a key role in long-term stability.
6. How can RAG enhance existing AI systems?
RAG can be integrated into current AI workflows to improve factual accuracy and response clarity. For instance, it can enhance chatbots, recommendation engines, and enterprise analytics tools by grounding outputs in verified knowledge, thus increasing reliability and user trust.
7. What’s the future of RAG in enterprise AI?
The future of RAG integration lies in multimodal and hybrid architectures, where systems can process text, images, and structured data together. As organizations prioritize real-time intelligence, RAG will continue to be central in creating adaptive, transparent, and data-driven AI ecosystems.



