
RAG Tutorial Introduction – The Game-Changer AI Didn’t Tell You About
In the rapidly evolving AI landscape, Retrieval-Augmented Generation (RAG) has quietly emerged as a game-changing approach that bridges the gap between large language models (LLMs) and the need for accurate, up-to-date, and context-aware responses. While many are still focused on fine-tuning models, this rag tutorial will show you how combining retrieval with generation can significantly boost performance without skyrocketing costs.
Unlike traditional AI systems that rely solely on pre-trained knowledge, RAG-powered applications pull relevant, real-world information from custom data sources before generating an answer. As a result, they reduce hallucinations, improve domain-specific accuracy, and deliver trustworthy outputs—even for complex, specialized queries.
Why This RAG Tutorial Matters Now
AI adoption is accelerating, yet many teams struggle with cost control, accuracy issues, and deployment complexity. Therefore, understanding and applying RAG is no longer optional—it’s a competitive necessity for developers, startups, and enterprises. This rag tutorial isn’t just theory; it’s a step-by-step guide to design, implement, and scale an unstoppable RAG-powered application.
Who Should Follow This RAG Tutorial
If you are a new AI enthusiast, junior developer, data scientist, startup founder, or enterprise AI engineer, this guide is designed for you. It blends technical clarity with practical strategies so that both beginners and experts can take immediate action.
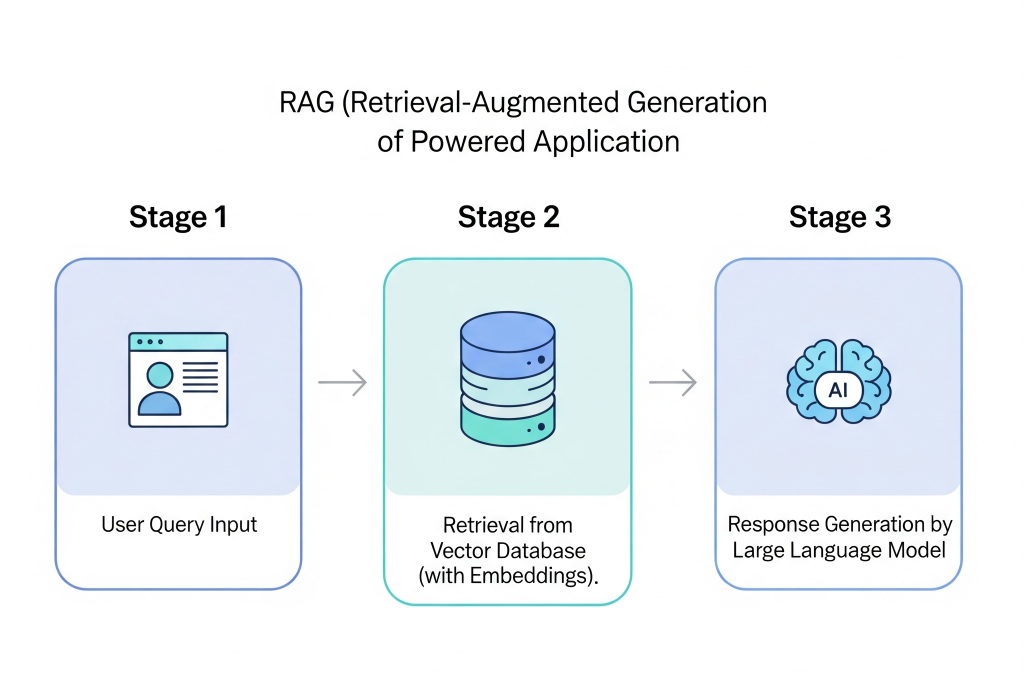
Visual Overview of RAG
Below is a simple architecture diagram showing how a RAG-powered application works—starting from a user query to delivering a precise, context-aware answer.
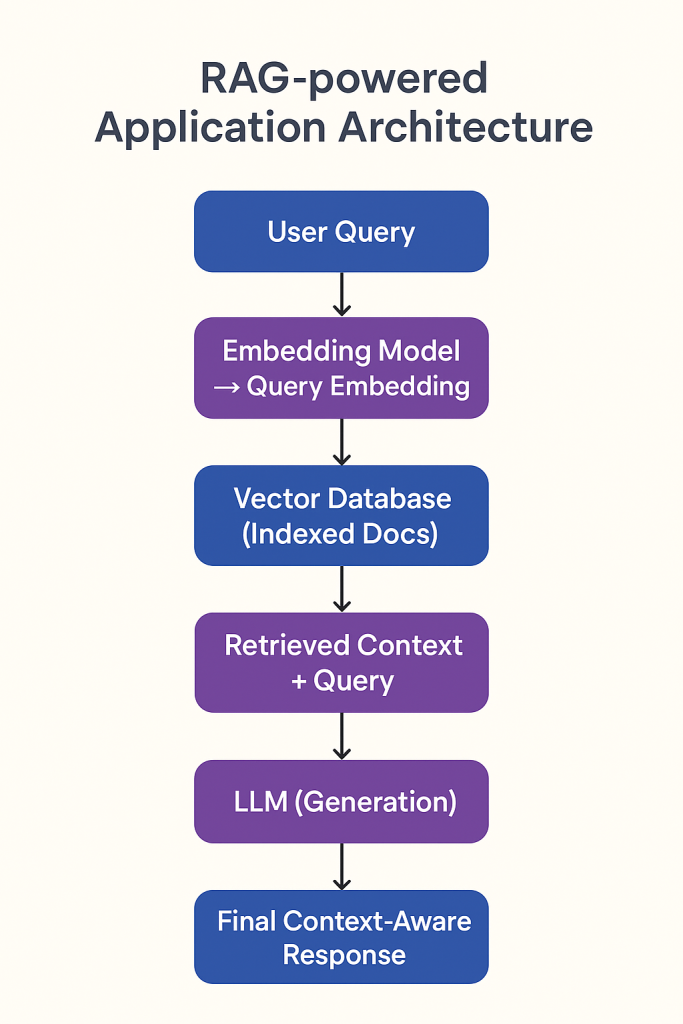
This pipeline will be expanded later in the rag tutorial with real code, advanced architectures, and optimization strategies.
RAG Tutorial – The Secret to Smarter AI
Building AI applications is no longer just about picking the most advanced large language model (LLM). This rag tutorial reveals how RAG-powered applications combine retrieval and generation to produce smarter, more reliable, and cost-effective AI solutions. Instead of relying solely on the model’s fixed training data, RAG queries a custom knowledge base or external source before generating responses. This ensures your AI remains accurate, current, and context-aware—qualities that can make or break a real-world deployment.
In domains where accuracy is critical, like law, medicine, finance, or technical support, RAG reduces risk while enhancing user trust. By strategically filtering and retrieving only what matters, you not only improve output quality but also cut down unnecessary processing—saving both time and money.
The Truth About Standard AI Models
Traditional AI models can sound authoritative, yet they hallucinate facts, rely on outdated knowledge, and often miss the finer points of a specific domain. While fine-tuning can help, it is expensive, static, and requires constant retraining. For teams handling rapidly changing information, this approach is inefficient and often unsustainable.
Why RAG Changes the Game
This rag tutorial highlights how RAG dynamically retrieves fresh and relevant context from a vector database or search index before passing it to the LLM. This process significantly reduces hallucinations, boosts domain accuracy, and enables the AI to respond to specialized and evolving queries. Whether answering employee policy questions in HR or delivering up-to-date market insights in finance, RAG adapts in real time without retraining the model—similar to innovations in AI in HR that boost workplace efficiency.
The Cost Advantage No One Talks About
One of RAG’s underappreciated strengths is cost efficiency. By narrowing the amount of information sent to the LLM, you:
- Save tokens in API calls, lowering per-query costs.
- Reduce compute load, especially if hosting locally.
- Maintain performance without paying for frequent model retraining.
Cost & Performance Comparison
| Feature | Standard LLM | RAG-Powered Application |
| Accuracy | Medium | High |
| API Cost per Query | High | Lower |
| Ability to Handle Context | Limited | Large & Targeted |
| Scalability | Medium | High |
Inside the RAG Engine – The Three Power Stages
Before diving deeper into building your own, this rag tutorial breaks RAG down into three core stages that work together to transform raw data into accurate, context-aware answers: Indexing, Retrieval, and Generation. Understanding these stages is essential because they determine your application’s speed, accuracy, and cost efficiency.
Data Indexing – Building Your AI’s Knowledge Library
In this stage, raw documents are cleaned, split into chunks, and embedded into numerical vectors so they can be stored in a vector database.
- Why it matters: Well-structured indexing improves retrieval accuracy and reduces noise.
- Example tools: LangChain, FAISS, Pinecone, Qdrant.
- Best practice: Use context-aware chunking rather than splitting by size alone to preserve meaning.
💻 Sample Python Snippet – Creating Embeddings
python
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts(docs, embeddings)Smart Retrieval – Finding the Gold in Your Data
Once indexed, your vector database is ready to find the most relevant chunks when a user asks a question. Retrieval is powered by similarity search, which compares the query embedding to stored embeddings.
- Why it matters: Precision here means less irrelevant data passed to the LLM, lowering costs and improving accuracy.
- Advanced tip: Use metadata filters to target specific document types, dates, or categories.
Intelligent Generation – Turning Context into Gold
This is where the magic happens. The retrieved chunks are combined with the user’s question and sent to the LLM for response generation.
- Why it matters: The LLM now answers using your curated, up-to-date knowledge rather than relying solely on its static training data.
- Prompting tip: Format your prompts so retrieved context is clearly separated from the question.
Step-by-Step RAG Tutorial – Build Your First Application from Scratch
Now that we’ve covered the theory, let’s put it into practice. This section of the rag tutorial walks you through the full process of creating your first RAG-powered application, with enough detail to help you avoid common mistakes and enough flexibility to adapt it for production later.
Setting Up Your Development Workspace
Your environment is the foundation of your RAG app. A poorly prepared workspace can lead to dependency issues, version conflicts, or even performance bottlenecks down the line.
What you need:
- Python 3.9+ – ensures compatibility with the latest AI libraries.
- Key dependencies:
- langchain for RAG orchestration.
- openai or another LLM API for text generation.
- faiss-cpu for local vector similarity search.
Installation Command:
bash
pip install langchain openai faiss-cpuScaling tip: For high-volume queries, consider a GPU-accelerated FAISS build or a managed vector database like Pinecone, Weaviate, or Qdrant—these handle millions of vectors with minimal slowdown.
Common setup pitfalls:
- Forgetting to set environment variables for your API key (OPENAI_API_KEY).
- Using an outdated Python version that causes package conflicts.
Preparing and Loading Your Data
Your AI’s intelligence depends entirely on the quality and relevance of the data you feed it. Garbage in, garbage out.
Best data sources:
- Company documentation (policies, procedures).
- Research papers and technical manuals.
- FAQs, customer support logs, or training materials—often managed through custom software solutions designed for secure knowledge handling.
Cleaning process:
- Remove duplicates.
- Fix formatting and encoding issues.
- Eliminate irrelevant or outdated content.
Example – Loading a text file:
python
from langchain.document_loaders import TextLoader
loader = TextLoader("data/employee_handbook.txt")
documents = loader.load()Pro tip: Use semantic chunking—splitting content where topics change—so retrieval results keep logical meaning instead of random sentence breaks.
Creating Embeddings and Storing Them
Embeddings are the “memory units” of your application—they convert text into high-dimensional vectors so that semantic similarity searches become possible.
Choosing an embedding model:
- Paid API (e.g., OpenAI) – very accurate, but costs scale with volume.
- Open-source (e.g., SentenceTransformers) – free, but may require more tuning.
Example:
python
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)Cost tip: For long-term storage of large datasets, use compressed embeddings to save memory without significantly losing accuracy.
Mistakes to avoid:
- Indexing raw, unprocessed text.
- Using overly small chunk sizes (loses context).
- Using overly large chunk sizes (increases token costs).
Retrieval and Prompt Construction
Retrieval is where the app finds relevant chunks from the vector database, and the prompt is how you tell the LLM to use that information.
Key retrieval parameter:
- k → number of chunks retrieved. Start with k=3 and adjust based on test results.
Example:
python
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=vector_store.as_retriever(search_kwargs={"k": 3}),
chain_type="stuff"
)
print(qa_chain.run("What is the company's remote work policy?"))Prompting best practices:
- Clearly separate the retrieved context from the user question.
- Add explicit instructions (e.g., “If the answer isn’t in the provided context, say so”).
- Keep prompts concise to stay within token limits.
Common issues:
- Context flooding: retrieving too many chunks, which makes the LLM less precise.
- Token overflow: sending so much text that the model cuts off mid-answer.
Adding Multi-Source Capability
A robust RAG app should handle diverse data types. This allows you to combine structured and unstructured data for richer responses.
Supported sources in LangChain:
- PDFs: PyPDFLoader
- CSVs: CSVLoader
- Websites: UnstructuredURLLoader
- Databases: SQL connectors or API calls
Use case: An HR chatbot that pulls from an employee handbook (PDF), payroll system (database), and internal HR policy webpage—similar to strategies used in AI employee engagement solutions..
Pro tip: Tag each document with metadata so you can filter retrieval based on source or category.
Performance, Scaling, and Deployment Considerations
If your prototype becomes a production tool, performance optimization is key.
Ways to scale effectively:
- Caching embeddings to speed up retrieval.
- Using asynchronous API calls to reduce latency.
- Batch processing queries instead of making one call per request.
Deployment trade-offs:
- Cloud hosting – Scales quickly but may have ongoing costs and privacy concerns.
- On-premise hosting – Lower recurring costs, better privacy, but higher setup complexity.
Avoiding Common Mistakes
- Indexing unclean data → leads to irrelevant answers.
Retrieving too many chunks → increases cost and reduces accuracy. - Ignoring token limits → causes truncated outputs.
- Skipping relevance tests → makes your RAG unreliable in real-world use.
Smarter, Leaner, Cheaper – Cost-Effective RAG Implementation
Building a RAG-powered application doesn’t have to drain your budget. In fact, when implemented strategically, it can be both powerful and affordable. In this section, we will explore practical techniques, database choices, and deployment strategies that help you get maximum value without overspending.
Understanding the Cost Drivers
Before you can save money, you must understand where the costs come from. In a typical RAG tutorial scenario, expenses are driven by:
- LLM API usage – The more tokens you send, the more you pay.
- Embedding generation – Paid embeddings can add up quickly for large datasets.
- Vector database hosting – Cloud-based vector stores charge for both storage and queries.
- Data preprocessing – May involve storage and compute costs if done in the cloud.
Transitioning from theory to practice, monitoring these cost drivers early prevents surprises later.
Choosing the Right Vector Database
Your choice of vector database can dramatically influence cost and speed. Let’s compare common options:
Vector Database Cost & Feature Comparison
| Vector DB | Hosting Type | Free Tier | Speed | Scalability | Best Use Case |
| FAISS | Local | Yes | High | Limited | Prototypes, local apps |
| Pinecone | Cloud | Limited | Very High | Unlimited | Scalable production apps |
| Weaviate | Cloud/Local | Yes | High | High | Hybrid deployments |
| Milvus | Local/Cloud | Yes | High | Very High | Enterprise-scale workloads |
Transition tip: If you’re starting small, FAISS keeps costs at zero; as your app grows, move to Pinecone or Milvus for scalability.
Reducing LLM API Costs
A well-designed rag tutorial workflow minimizes API usage while still maintaining quality.
- Retrieve less data: Reduce the k value in retrieval to avoid unnecessary tokens.
- Filter by metadata: Send only context relevant to the query.
- Use smaller models for simple queries: Not every request needs GPT-4-level power.
- Batch process requests: For high-volume systems, process multiple queries in one call.
Smoothly moving from setup to scaling, you can integrate caching layers that store previous responses to avoid re-querying the LLM.
Cloud vs Local Hosting – The Trade-Offs
Your hosting decision can change both cost structure and performance.
| Hosting Type | Pros | Cons |
| Cloud | Easy to scale, no hardware maintenance | Recurring costs, potential privacy risks |
| Local | One-time hardware cost, data privacy | Limited scalability, higher setup time |
| Hybrid | Balanced cost, flexible scaling | Requires technical setup, potential complexity |
Transitioning from prototype to production, many teams start local for privacy and then move to hybrid for scaling without losing control over sensitive data.
Performance Tuning for Cost Efficiency
Optimizing performance isn’t just about speed—it directly impacts your budget.
- Pre-compute embeddings offline to save on real-time compute.
- Compress embeddings for storage efficiency.
- Tune chunk size to minimize token usage while keeping answers complete.
- Asynchronous retrieval to avoid blocking the system during heavy loads.
From theory to measurable savings, these optimizations can cut costs by 20–50% in production environments.
Knowing When to Scale
Scaling too early wastes resources, while scaling too late risks slow performance.
- Scale when query volume starts causing latency.
- Upgrade your vector DB when storage size approaches capacity.
- Switch to GPU or cloud when retrieval speed is slowing down user experience.
Smooth growth over sudden expansion ensures cost stability without sacrificing performance.
Advanced RAG Implementation Strategies – Going Beyond the Basics
Once your RAG-powered application is running reliably, the next step is to move from functional setups to truly optimized systems. This section covers advanced design patterns, performance enhancements, and hybrid architectures that provide clear advantages in speed, accuracy, and adaptability.
Multi-Query Pipelines for Complex Questions
When users ask multi-part or ambiguous questions, a single retrieval pass may miss important details.
- Break down complex questions into multiple sub-queries.
- Execute sub-queries in parallel for faster processing.
- Aggregate the retrieved results before sending them to the language model.
This approach significantly improves the completeness of responses, especially in enterprise knowledge management and research-heavy environments.
Hybrid Search – Combining Keyword and Semantic Matching
While semantic search is excellent for nuanced queries, keyword search often provides faster and more precise results for specific terms.
- Integrate BM25 keyword search with vector embeddings.
- Use keyword matches for exact data retrieval and semantic matches for conceptual relevance.
- Implement a re-ranking system to prioritize high-confidence results.
This combination delivers both high recall and high precision, making it effective in large, diverse datasets.
Domain-Specific Fine-Tuning
Generic embeddings work well for general topics, but fine-tuning on domain-specific data can dramatically improve accuracy.
- Gather relevant domain materials such as industry reports, internal documentation, or regulatory texts.
- Fine-tune either the embedding model or a smaller LLM to increase contextual relevance.
Although fine-tuning requires additional time and resources, it often results in more precise and trustworthy answers in specialized fields.
Context-Aware Retrieval
Instead of treating every query as isolated, context-aware retrieval maintains continuity across interactions.
- Store recent queries and relevant responses in a temporary memory buffer.
- Inject this contextual history into retrieval prompts for follow-up questions.
- Limit the size of the memory buffer to prevent context drift.
This technique creates more natural, human-like interactions and is particularly effective for conversational assistants.
Caching Strategies to Reduce Latency and Cost
Many queries in production environments are repetitive. Implementing caching avoids unnecessary computation.
- Response caching stores final outputs for repeated questions.
- Embedding caching prevents reprocessing unchanged documents.
- Vector store snapshots enable quick rollbacks and testing.
Moving from constant computation to intelligent reuse can reduce operational costs by a significant margin while improving response times.
Monitoring and Continuous Improvement
A RAG system should evolve alongside its data and usage patterns.
- Track retrieval accuracy, latency, and user satisfaction.
- Log and review low-confidence answers for targeted improvement.
- Regularly refresh or retrain embeddings to keep pace with new information.
This ongoing feedback and refinement cycle ensures that your application remains effective and competitive over time.
Current Trends in RAG Adoption
RAG-powered applications are no longer confined to experimental projects. They are now integrated into business-critical workflows across various industries.
- Customer Service: Instead of relying on static FAQ pages, companies are building RAG-driven chatbots capable of pulling precise, context-aware answers from a knowledge base. This improves customer satisfaction while reducing support costs.
- Research and Academia: Researchers use RAG to synthesize findings from multiple papers, enabling faster literature reviews and informed decision-making.
- Enterprise Knowledge Management: Organizations store massive amounts of documents, policies, and procedures. RAG streamlines access to this information by offering conversational search instead of traditional keyword-based systems.
The transition from generic AI models to RAG represents a shift toward domain-aware AI—a capability that delivers not just accuracy but also trustworthiness.
Emerging Innovations in RAG
As the technology matures, developers are experimenting with new approaches that go beyond text retrieval.
- Multimodal RAG: Integrating video, audio, and images into retrieval workflows, enabling richer responses for fields like e-learning and healthcare.
- Real-Time RAG: Linking to live data feeds (e.g., stock prices, breaking news) for instant updates instead of relying solely on static datasets.
- Agent-Driven RAG: Combining retrieval with AI agents that can act—such as filling out forms, scheduling meetings, or drafting documents—based on retrieved context.
These innovations will enable RAG systems to handle more complex, interactive tasks, pushing them into new domains like decision support systems and automated compliance monitoring.
Known Limitations of RAG
Despite its advantages, RAG is not perfect. Recognizing its weaknesses is crucial for effective implementation.
Challenges to address:
- Data Quality Dependency: If the source material is outdated or poorly structured, retrieval accuracy will suffer.
- Latency Concerns: Large-scale retrieval and generation pipelines can slow response times, especially without caching or indexing optimizations.
- Operational Costs: Heavy API usage for both retrieval and LLM calls can become expensive at scale.
- Embedding Model Quality: Weak or poorly trained embeddings will undermine the entire retrieval process, no matter how powerful the LLM is.
Mitigation strategies:
- Keep datasets regularly updated and well-organized.
- Optimize retrieval parameters (e.g., chunk size, search filters).
- Monitor and manage API usage to control expenses.
The Future of RAG
The future of RAG is pointing toward self-learning, more secure, and hybrid AI systems.
Expected developments:
- Self-Improving Retrieval Loops: Continuous learning from user feedback to refine retrieval accuracy over time.
- Hybrid Intelligence Models: Combining AI’s retrieval capabilities with human review for high-stakes use cases such as law or medicine.
Federated RAG: Allowing AI to securely retrieve data from multiple sources without centralizing sensitive information, addressing privacy concerns.
As AI becomes more deeply integrated into enterprise workflows, RAG is set to become the default architecture for applications requiring fact-based, domain-specific responses.
Conclusion
RAG has already proven itself as a game-changing approach for enhancing large language models with reliable, domain-specific information. From boosting customer service efficiency to powering research tools and enterprise search, it offers a flexible, scalable way to make AI truly useful in real-world environments.
By understanding current trends, staying ahead of innovations, addressing known limitations, and anticipating future developments, developers and businesses can ensure they remain competitive in an AI-driven landscape.
In the context of this rag tutorial, these insights provide not just a blueprint for building applications, but also a strategic roadmap for sustaining and improving them over time.
Frequently Asked Questions (FAQs)
1. What is a RAG-powered application?
A RAG-powered application combines a retrieval system with a generative AI model. It first searches a knowledge base for relevant information, then uses an AI model to generate a detailed, context-aware response. This approach improves accuracy and ensures outputs are grounded in real, domain-specific data.
2. Who should follow this rag tutorial?
This rag tutorial is aimed at AI beginners, Python developers, data scientists, startup teams, and enterprise developers. It is also valuable for technical students and AI engineers who want to understand both the fundamentals and advanced strategies for building scalable RAG-powered applications.
3. How much does it cost to run a RAG application?
The cost varies depending on API usage, embedding generation, and hosting choices. A local setup using free tools like FAISS can be nearly cost-free, while cloud-based enterprise deployments with high traffic and large datasets may run into hundreds of dollars monthly. Costs can be controlled with optimization strategies.
4. Can I use RAG with private company data?
Yes. RAG works well with secure, internal datasets when combined with the right hosting and encryption measures. Many organizations use on-premise or hybrid deployments to maintain control over sensitive information while benefiting from AI-powered retrieval.
5. What are the main challenges of RAG?
RAG systems face challenges such as reliance on high-quality, updated data, potential retrieval latency, and rising API costs at scale. These can be mitigated through caching strategies, metadata filtering, regular data updates, and tuning retrieval parameters for efficiency.



